
Definition of Data Staging
Your staging area, or landing zone, is an intermediate storage area used for data processing during the extract, transform and load (ETL) process. The data staging area sits between your data source(s) and your data target(s), which are often data warehouses, data marts, or other data repositories. For purposes of this discussion, a data lake is also considered a staging environment where data is persisted in its natural state.
Data staging areas are either transient in nature or persisted to hold data for extended periods of time for archival, maintain history for point-in-time reporting and troubleshooting:
- For transient objects, their content is erased prior to running an ETL process or immediately following successful completion of an ETL process.
- For persisted objects, history is captured and changed data capture (CDC) is managed for all source attributes.
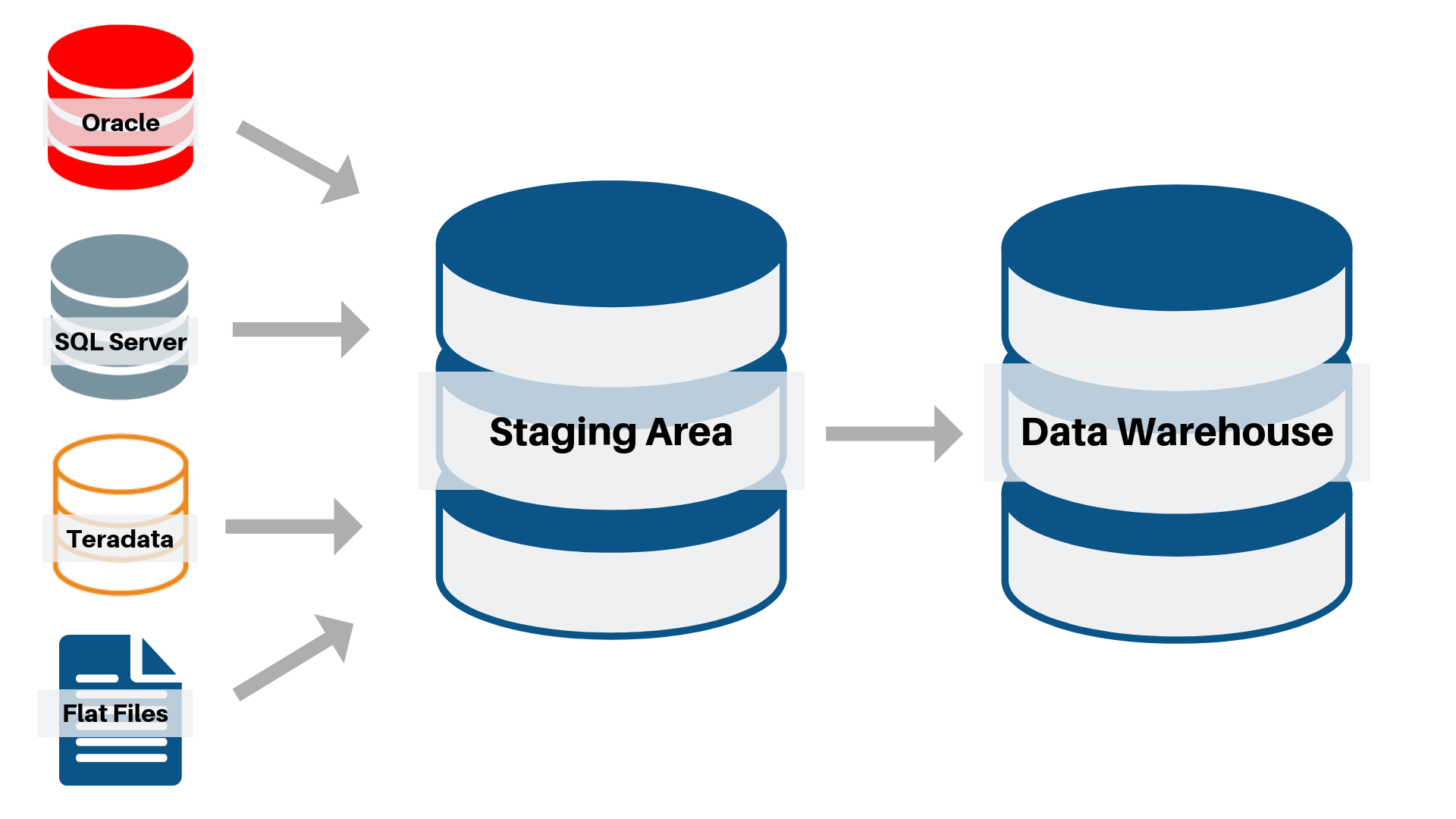
The Process of Data Staging
Staging areas can be implemented in the form of tables in relational databases, text-based flat files (or XML files) or proprietary formatted binary files stored in file systems. Staging area architectures range in complexity from a set of simple relational tables to self-contained database instances or file systems. It is common to tag data in the staging area with additional metadata indicating the source of origin, timestamps indicating when the data was placed and control information defining when the data was changed.
Staging areas are designed to provide many benefits, but the primary motivations for their use are to increase the efficiency of ETL processes, ensure data integrity, maintain snapshot data for longitudinal reporting and support data quality operations. Common functions of the staging area include:
- Consolidation – One of the primary functions performed by a staging area is the consolidation of data from multiple source systems
- Alignment – Aligning data includes standardization of reference data across multiple source systems, often acting in support of, master data management capabilities
- Minimizing contention – The staging area minimizes contention within source systems and provides a greater degree of control over concurrency
- Varied Latency – The staging area can support hosting of data to be processed on independent schedules and different latencies
- Change detection – The process to maintain the staging area supports flexible change detection operations
- Troubleshooting – For the persisted architecture, since the history of changed data is captured for extended periods of time to support technical troubleshooting
- Capturing Point-in-time Changes in Data – Capturing and managing changes in data for a given point in time is a critical requirement for longitudinal and latitudinal reporting, a data warehouse manages the history of changed data
- Extended Reporting – Late binding, non-predictive and ad-hoc reporting can be satisfied by directly querying the stage area.
Business Challenges
As an information-driven organization, your stakeholders thirst for information is constantly growing. Information must be made available quickly, it must be transparent, reliable, non-volatile and sufficiently accurate. The industry push is to automate the science of data staging and free your resources to focus on analyzing your corporate information.
The common process of manually developing scripts or using an ETL tool for point-to-point data staging routines is costly and requires a lot of resource commitment. Since this code is developed manually a lot of governance and QA is required to ensure quality. Additionally, source systems are always in a state of flux thus your developers are constantly maintaining existing programs. This manual approach of developing and maintaining your data staging environment is resource and time-consuming. The technology investments are high to:
- capture the necessary technical and operational metadata
- map the multisource data types
- develop data type conversions as part of the source to target mapping
- develop change data detection from disparate source systems
- optimize extraction and load routines
- establish the transaction and error logs
- manage a robust process and load control
- program for flexible design patterns.
Common Data Issues are Eliminated with A2B Data™
Since data staging is the foundation of your analytical environment, the following is often realized with a weak data staging architecture:
- your data lake has turned into a data swamp
- you do not capture sufficient technical and operational metadata
- your project times are elongated, and project risks are high
- data quality is hampered as the code is manually developed
- your data delivery cannot meet business demands
- development times are slow
- requires rigid development life cycles
- your enterprise reporting is limited
- point in time analytics is not possible as history of changed data is not captured
- your stakeholder confidence is lessened.
Achieve Active Data Staging with A2B Data™
A2B Data™ was built to actively manage the Data Staging environment for companies seeking a solid data foundation. Actively managing your end-to-end data staging process is the cornerstone of A2B Data™ functionality. The program automates the extract and load process and it does this without the need for you to maintain any code. In fact, A2B Data™ will dynamically generate the code by reading the metadata of both source and target and applying the built-in design patterns.
A2B Data™ automates the heavy lifting of mapping, extracting and loading your heterogenous source data to any target platform. It generates detailed operational statistics, processes technical lineage, utilizes a robust set of CDC methods and performs impact analysis on the metadata. Unlike the traditional method of manually comparing the source to target mappings, A2B Data™ queries its proprietary metamodel to determine changes in the data dictionary, column level lineage, and log file analysis.
The product supports both the transient and persisted staging architecture, with your choice of the following target design patterns:
- Truncate and Reload – this supports the transient method
- Type 2 SCD (Slowly Changing Dimension) – creates a new record every time a change of data is observed for a natural key of a source table
- Type 1 SCD –if the record is changed for a natural key of a source table then it updates it, otherwise, it writes a new record (like MERGE or “UPSERT”).
- Append – appends to the last row with a new transaction date.
Advantages of A2B Data™
By utilizing A2B Data™ to actively manage your Data Staging process you are guaranteed to save an enormous amount of time, money and achieve stakeholder confidence as your data is staged quickly, with zero errors generated and stakeholder confidence guaranteed. The following are some of the key customer observations in leveraging A2B Data™ in their environments:
- Faster Data Extraction – Data is moved efficiently by processing Changed Data Capture (CDC)
- Improved Data Quality – Nullify data quality issues with dynamically generated code
- Reduced Programmer Cost – No code is maintained as A2B Data™ dynamically generates the code for you
- Optimized Architecture – Bi-directionally process your data from any source to any target database
- Enhanced Process Controls – Operational and technical metadata is automatically tracked
- Streamlined Trouble-Shooting – Granular log files and statistics are available for reporting
- Cyber Security Model – Data transmissions are secure, and your data never leaves your firewall
- Project risks are minimized – Metadata driven logic ensures 100% consistency
- Improved Historical Reporting – history of changed data is tracked and stored for every table thus allowing point-in-time reporting.